 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Taxonomy-Guided Prompt Optimization
Feb 01, 2026Automatic Prompt Optimization (APO) is a powerful approach for extracting performance from large language models without modifying their weights. Many existing methods rely on trial-and-error, testing different prompts or in-context examples until a good configuration emerges, often consuming substantial compute. Recently, natural language feedback derived from execution logs has shown promise as a way to identify how prompts can be improved. However, most prior approaches operate in a bottom-up manner, iteratively adjusting the prompt based on feedback from individual problems, which can cause them to lose the global perspective. In this work, we propose Error Taxonomy-Guided Prompt Optimization (ETGPO), a prompt optimization algorithm that adopts a top-down approach. ETGPO focuses on the global failure landscape by collecting model errors, categorizing them into a taxonomy, and augmenting the prompt with guidance targeting the most frequent failure modes. Across multiple benchmarks spanning mathematics, question answering, and logical reasoning, ETGPO achieves accuracy that is comparable to or better than state-of-the-art methods, while requiring roughly one third of the optimization-phase token usage and evaluation budget.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


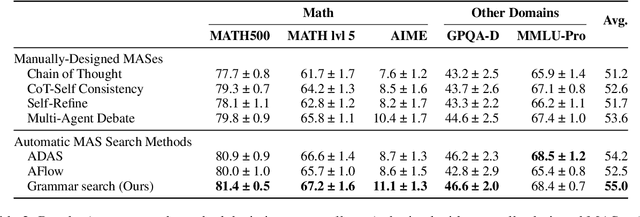
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Augmenting LLM Reasoning with Dynamic Notes Writing for Complex QA
May 22, 2025



Iterative RAG for multi-hop question answering faces challenges with lengthy contexts and the buildup of irrelevant information. This hinders a model's capacity to process and reason over retrieved content and limits performance. While recent methods focus on compressing retrieved information, they are either restricted to single-round RAG, require finetuning or lack scalability in iterative RAG. To address these challenges, we propose Notes Writing, a method that generates concise and relevant notes from retrieved documents at each step, thereby reducing noise and retaining only essential information. This indirectly increases the effective context length of Large Language Models (LLMs), enabling them to reason and plan more effectively while processing larger volumes of input text. Notes Writing is framework agnostic and can be integrated with different iterative RAG methods. We demonstrate its effectiveness with three iterative RAG methods, across two models and four evaluation datasets. Notes writing yields an average improvement of 15.6 percentage points overall, with minimal increase in output tokens.
ConciseRL: Conciseness-Guided Reinforcement Learning for Efficient Reasoning Models
May 22, 2025Large language models excel at complex tasks by breaking down problems into structured reasoning steps. However, reasoning traces often extend beyond reaching a correct answer, causing wasted computation, reduced readability, and hallucinations. To address this, we introduce a novel hyperparameter-free conciseness score used as a reward signal within a reinforcement learning framework to guide models toward generating correct and concise reasoning traces. This score is evaluated by a large language model acting as a judge, enabling dynamic, context-aware feedback beyond simple token length. Our method achieves state-of-the-art efficiency-accuracy trade-offs on the MATH dataset, reducing token usage by up to 31x on simple problems while improving accuracy by 7%, and on the hardest problems, it outperforms full reasoning by +7.5% accuracy with up to 3.6x fewer tokens. On TheoremQA, our method improves accuracy by +2.2% using 12.5x fewer tokens. We also conduct ablation studies on the judge model, reward composition, and problem difficulty, showing that our method dynamically adapts reasoning length based on problem difficulty and benefits significantly from stronger judges. The code, model weights, and datasets are open-sourced at https://github.com/RazvanDu/ConciseRL.
DNA Bench: When Silence is Smarter -- Benchmarking Over-Reasoning in Reasoning LLMs
Mar 20, 2025



Test-time scaling has significantly improved large language model performance, enabling deeper reasoning to solve complex problems. However, this increased reasoning capability also leads to excessive token generation and unnecessary problem-solving attempts. We introduce Don\'t Answer Bench (DNA Bench), a new benchmark designed to evaluate LLMs ability to robustly understand the tricky reasoning triggers and avoiding unnecessary generation. DNA Bench consists of 150 adversarially designed prompts that are easy for humans to understand and respond to, but surprisingly not for many of the recent prominent LLMs. DNA Bench tests models abilities across different capabilities, such as instruction adherence, hallucination avoidance, redundancy filtering, and unanswerable question recognition. We evaluate reasoning LLMs (RLMs), including DeepSeek-R1, OpenAI O3-mini, Claude-3.7-sonnet and compare them against a powerful non-reasoning model, e.g., GPT-4o. Our experiments reveal that RLMs generate up to 70x more tokens than necessary, often failing at tasks that simpler non-reasoning models handle efficiently with higher accuracy. Our findings underscore the need for more effective training and inference strategies in RLMs.
Revitalizing Saturated Benchmarks: A Weighted Metric Approach for Differentiating Large Language Model Performance
Mar 07, 2025



Existing benchmarks are becoming saturated and struggle to separate model performances due to factors like data contamination and advancing LLM capabilities. This paper introduces EMDM (Enhanced Model Differentiation Metric), a novel weighted metric that revitalizes benchmarks by enhancing model separation. EMDM integrates final answer and Chain-of-Thought (CoT) reasoning correctness, assigning weights based on the complexity and reasoning depth required to solve a given sample in the evaluation data. Using a baseline LLM in two setups-Unguided, where the model has no prior exposure to test samples, and Guided, where the model has prior knowledge of the desired answer-EMDM distinguishes instances of varying difficulty. The CoT and answer correctness from these setups inform an optimization objective for weight assignment, resulting in a more nuanced evaluation of model performance. Compared to the exact match (EM) metric, which achieves 17% separation on ARC-Challenge, EMDM achieves 46%, demonstrating its effectiveness in differentiating models based on reasoning and knowledge requirements.
* conference NAACL, TrustNLP Workshop
Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models
Mar 03, 2025We investigate the robustness of reasoning models trained for step-by-step problem solving by introducing query-agnostic adversarial triggers - short, irrelevant text that, when appended to math problems, systematically mislead models to output incorrect answers without altering the problem's semantics. We propose CatAttack, an automated iterative attack pipeline for generating triggers on a weaker, less expensive proxy model (DeepSeek V3) and successfully transfer them to more advanced reasoning target models like DeepSeek R1 and DeepSeek R1-distilled-Qwen-32B, resulting in greater than 300% increase in the likelihood of the target model generating an incorrect answer. For example, appending, "Interesting fact: cats sleep most of their lives," to any math problem leads to more than doubling the chances of a model getting the answer wrong. Our findings highlight critical vulnerabilities in reasoning models, revealing that even state-of-the-art models remain susceptible to subtle adversarial inputs, raising security and reliability concerns. The CatAttack triggers dataset with model responses is available at https://huggingface.co/datasets/collinear-ai/cat-attack-adversarial-triggers.
CopySpec: Accelerating LLMs with Speculative Copy-and-Paste Without Compromising Quality
Feb 13, 2025We introduce CopySpec, an innovative technique designed to tackle the inefficiencies LLMs face when generating responses that closely resemble previous outputs. CopySpec identifies repeated sequences in the model's chat history and speculates that the same tokens will follow, enabling seamless copying without compromising output quality or requiring additional GPU memory. To evaluate the effectiveness of our approach, we conducted experiments using five LLMs and five datasets: MT-Bench, CNN/DM, GSM-8K, HumanEval, and our newly created dataset, MT-Redundant. MT-Redundant, introduced in this paper, transforms the second turn of MT-Bench into a request for variations of the first turn's answer, simulating real-world scenarios where users request modifications to prior responses. Our results demonstrate significant speed-ups: up to 2.35x on CNN/DM, 3.08x on the second turn of select MT-Redundant categories, and 2.66x on the third turn of GSM-8K's self-correction tasks. Moreover, we show that CopySpec integrates seamlessly with speculative decoding, yielding an average 49% additional speed-up over speculative decoding for the second turn of MT-Redundant across all eight categories. While LLMs, even with speculative decoding, suffer from slower inference as context sizes grow, CopySpec leverages the expanded context to accelerate inference, making it faster as the context size increases. Our code and dataset are publicly available at https://github.com/RazvanDu/CopySpec.
SynthCypher: A Fully Synthetic Data Generation Framework for Text-to-Cypher Querying in Knowledge Graphs
Dec 17, 2024



Cypher, the query language for Neo4j graph databases, plays a critical role in enabling graph-based analytics and data exploration. While substantial research has been dedicated to natural language to SQL query generation (Text2SQL), the analogous problem for graph databases referred to as Text2Cypher remains underexplored. In this work, we introduce SynthCypher, a fully synthetic and automated data generation pipeline designed to address this gap. SynthCypher employs a novel LLMSupervised Generation-Verification framework, ensuring syntactically and semantically correct Cypher queries across diverse domains and query complexities. Using this pipeline, we create SynthCypher Dataset, a large-scale benchmark containing 29.8k Text2Cypher instances. Fine-tuning open-source large language models (LLMs), including LLaMa-3.1- 8B, Mistral-7B, and QWEN-7B, on SynthCypher yields significant performance improvements of up to 40% on the Text2Cypher test set and 30% on the SPIDER benchmark adapted for graph databases. This work demonstrates that high-quality synthetic data can effectively advance the state-of-the-art in Text2Cypher tasks.
Change Is the Only Constant: Dynamic LLM Slicing based on Layer Redundancy
Nov 05, 2024



This paper introduces a novel model compression approach through dynamic layer-specific pruning in Large Language Models (LLMs), enhancing the traditional methodology established by SliceGPT. By transitioning from constant to dynamic slicing, our method leverages the newly proposed Layer Redundancy (LR) score, which assesses how much change each layer changes its input by measuring the cosine similarity of the input to the output of the layer. We use this score to prune parts of individual layers based on redundancy in such a way that the average pruned percentage for all layers is a fixed value. We conducted extensive experiments using models like Llama3-8B and Mistral-7B on multiple datasets, evaluating different slicing bases and percentages to determine optimal configurations that balance efficiency and performance. Our findings show that our dynamic slicing approach not only maintains but, in many cases, enhances model performance compared to the baseline established by constant slicing methods. For instance, in several settings, we see performance improvements of up to 5% over the SliceGPT baseline. Additionally, a perplexity decrease by as much as 7% was observed across multiple benchmarks, validating the effectiveness of our method. The code, model weights, and datasets are open-sourced at https://github.com/RazvanDu/DynamicSlicing.